Saturday afternoon, July 25, was quite magical for me: all three beautiful talks were closely related to my interests and to my own work. Here is a brief personal description of the lectures, with links to the slides and papers, … Continue reading →
Saturday afternoon, July 25, was quite magical for me: all three beautiful talks were closely related to my interests and to my own work. Here is a brief personal description of the lectures, with links to the slides and papers, followed by a more detailed account of each talk.
Jinyoung Park gave a beautiful talk entitled “Thresholds,” concerning an array of conjectures about the location of thresholds for monotone properties and some of their applications. She concentrated on three conjectures: the Kahn–Kalai conjecture, also known as the expectation-threshold conjecture; the second Kahn–Kalai conjecture; and Talagrand’s discrete convexity conjecture. Here are the links to the proceedings paper and the slides.
Tom Braden and Nicholas Proudfoot gave a beautiful talk entitled “Intersection Cohomology Without Spaces,” devoted to a major theme in algebraic combinatorics: geometric structures can survive, and remain powerful, even in settings where the geometry itself does not exist. They discussed three examples: Kazhdan–Lusztig polynomials for Coxeter groups, toric  -polynomials for polytopes, and Kazhdan–Lusztig–Stanley polynomials for matroids. Here are the links to the proceedings paper and to the slides.
-polynomials for polytopes, and Kazhdan–Lusztig–Stanley polynomials for matroids. Here are the links to the proceedings paper and to the slides.
Raghu Meka gave a beautiful talk entitled “Structure vs Randomness Redux.” The talk focused mainly on the new bounds of Meka and Zander Kelley for the density of sets of integers containing no three-term arithmetic progression. In my view, this is among the most important mathematical results of the past few years. The method relies on a new version of the “structure versus randomness” paradigm, and it has led to important progress in both additive combinatorics and theoretical computer science. Here are the links to the proceedings paper and the slides.
Breaking news
On another matter: OpenAI reported today on the solution of ten major mathematical problems.
Some personal comments
- I wrote about the Kahn–Kalai conjecture in several earlier posts. (In my lectures and posts, I was often imprecise about the distinction between the first and second conjectures.) Although both Jeff and I were skeptical about the conjecture, in our paper we proposed a program for proving it based on strong inverse forms of discrete isoperimetric inequalities. The central inverse conjecture, Conjecture 6(a) in our paper, is still open, although some stronger versions (6(b) and 6(c)) turned out to be false. Another part of the program, Conjecture 7, was also refuted. This was the subject of our first AI+Polymath project, in which the counterexample was found with the help of AI; see this post.
- Of the three topics discussed by Tom and Nicholas, the one I have studied most closely is the second: toric -vectors of polytopes. Beyond the major achievement of extending the theory from rational polytopes to arbitrary polytopes, an important remaining challenge is to extend it further to strongly regular CW-spheres—that is, regular CW-spheres in which the intersection of any two cells is itself a cell. Karim Adiprasito’s solution of the -conjecture for triangulated spheres—see this post and this one—may offer hope in this direction. Another important problem is to understand the combinatorial consequences of the results arising from algebraic geometry, whether “with spaces” or “without spaces.” See also this post.
- I have followed progress on Roth’s theorem and Szemerédi’s theorem for many years, including here on the blog. (I reported on the Kelley-Meka breakthrough in this 2023 post, and see, for example, also this 2020 post; this 2010 post; this 2009 post; , and this 2016 post.) From time to time, I even tried to work on these problems myself.
- I have many fond memories connected with the mathematics of these three lectures, with the speakers, and with many of the other mathematicians involved.
Let me move now to a more detailed description of the three talks.

With Jinyoung Park and Hari Bercovici
Jinyoung Park: Thresholds
Jinyoung Park’s lecture, simply titled “Thresholds,” was organized around the question: What drives thresholds? Let  be a finite set and let
be a finite set and let 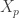 be the random subset obtained by choosing every element independently with probability
be the random subset obtained by choosing every element independently with probability  . For an increasing family
. For an increasing family  , its threshold
, its threshold  is defined by
is defined by  . A basic lower bound comes from the first-moment method. We call
. A basic lower bound comes from the first-moment method. We call 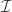 -small if it can be covered by simple witnesses
-small if it can be covered by simple witnesses  whose total expected contribution satisfies
whose total expected contribution satisfies  , and we let
, and we let  be the largest such . Park discussed three fundamental questions concerning the relation between this simple expectation bound and the actual threshold.
be the largest such . Park discussed three fundamental questions concerning the relation between this simple expectation bound and the actual threshold.
The first question was the Kahn–Kalai conjecture, which asserted that the first-moment bound always determines the threshold up to a logarithmic factor. In its strengthened form, proved by Park and Huy Tuan Pham,

where  is the size of the largest minimal member of . Earlier, Keith Frankston, Jeff Kahn, Bhargav Narayanan, and Park had proved Talagrand’s fractional version, replacing ordinary covers by fractional covers. The dual language of spread measures turned out to be particularly powerful: once one constructs a probability distribution on the desired combinatorial structures for which no fixed set of elements occurs too often, the threshold theorem can be applied. This circle of ideas gives remarkably short routes to the correct threshold orders for perfect hypergraph matchings, Hamiltonian cycles, bounded-degree spanning trees, and several other difficult problems. The logarithmic factor cannot in general be removed, as illustrated by coupon-collector phenomena.
is the size of the largest minimal member of . Earlier, Keith Frankston, Jeff Kahn, Bhargav Narayanan, and Park had proved Talagrand’s fractional version, replacing ordinary covers by fractional covers. The dual language of spread measures turned out to be particularly powerful: once one constructs a probability distribution on the desired combinatorial structures for which no fixed set of elements occurs too often, the threshold theorem can be applied. This circle of ideas gives remarkably short routes to the correct threshold orders for perfect hypergraph matchings, Hamiltonian cycles, bounded-degree spanning trees, and several other difficult problems. The logarithmic factor cannot in general be removed, as illustrated by coupon-collector phenomena.
The second Kahn–Kalai conjecture is more concrete and remains open. Given a graph  , let
, let  be the smallest for which the expected number of copies in
be the smallest for which the expected number of copies in  of every subgraph
of every subgraph  is at least
is at least  . Clearly
. Clearly  , and the conjecture asserts that
, and the conjecture asserts that

where  is the number of vertices of . This is stronger than the general theorem because it asks us to use only the obvious subgraph witnesses, rather than arbitrary and possibly nonsymmetric covers. Recent work of Quentin Dubroff, Jeff Kahn, and Park proves the bound with an additional factor
is the number of vertices of . This is stronger than the general theorem because it asks us to use only the obvious subgraph witnesses, rather than arbitrary and possibly nonsymmetric covers. Recent work of Quentin Dubroff, Jeff Kahn, and Park proves the bound with an additional factor  , and proves the conjectured bound itself in the sparse regime
, and proves the conjectured bound itself in the sparse regime  . Thus the remaining question is whether the complicated abstract witnesses defining can always be replaced, at constant cost, by the natural subgraphs of .
. Thus the remaining question is whether the complicated abstract witnesses defining can always be replaced, at constant cost, by the natural subgraphs of .
Park’s third theme was Talagrand’s discrete convexity conjecture. For a decreasing family  , let
, let

and let  .
.
The conjecture says that there are universal constants  and
and  such that, whenever
such that, whenever 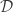 has sufficiently large
has sufficiently large 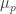 -measure, the exceptional family
-measure, the exceptional family  is
is  -small. In words, boundedly many unions of members of a large decreasing family should cover almost the entire discrete cube, apart from an exceptional set whose smallness has an explicit first-moment explanation. The Park–Pham theorem gives a related statement with
-small. In words, boundedly many unions of members of a large decreasing family should cover almost the entire discrete cube, apart from an exceptional set whose smallness has an explicit first-moment explanation. The Park–Pham theorem gives a related statement with 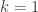 but with a necessary logarithmic loss in ; Talagrand’s conjecture predicts that allowing a bounded number of unions eliminates this loss. Talagrand described this as his “lifetime favorite problem,” and it remains open.
but with a necessary logarithmic loss in ; Talagrand’s conjecture predicts that allowing a bounded number of unions eliminates this loss. Talagrand described this as his “lifetime favorite problem,” and it remains open.

Tom Braden, Nicholas Proudfoot, with Pierre Deligne and George Lusztig
Tom Braden and Nicholas Proudfoot: Intersection Cohomology Without Spaces.
The second lecture, by Tom Braden and Nicholas Proudfoot, was entitled “Intersection Cohomology Without Spaces.” Ordinary cohomology behaves beautifully for smooth projective varieties, satisfying Poincaré duality, the hard Lefschetz theorem, and the Hodge–Riemann relations. For singular varieties, ordinary cohomology may lose these properties, but intersection cohomology restores them. Besides the global groups  one has local intersection cohomology groups
one has local intersection cohomology groups  , which measure the singularity of near . Their graded dimensions often assemble into polynomials of central importance in combinatorics and representation theory.
, which measure the singularity of near . Their graded dimensions often assemble into polynomials of central importance in combinatorics and representation theory.
Braden and Proudfoot presented three parallel examples. For Coxeter groups one obtains the Kazhdan–Lusztig polynomials; for convex polytopes one obtains Stanley’s -polynomials; and for matroids one obtains the Kazhdan–Lusztig polynomials of matroids. All three belong to Stanley’s general theory of Kazhdan–Lusztig–Stanley, or KLS, polynomials associated with a ranked poset and a suitable collection of polynomials called a  -kernel. The KLS-polynomials
-kernel. The KLS-polynomials  are defined recursively, together with the crucial degree condition
are defined recursively, together with the crucial degree condition

From their recursive definitions it is far from evident that their coefficients should be nonnegative. Geometry explains this by identifying them with Poincaré polynomials

of appropriate local intersection cohomology groups.
The relevant geometric spaces exist only in special cases. For Weyl groups they are Schubert varieties in flag varieties; for rational polytopes they are toric varieties; and for realizable matroids they are arrangement Schubert varieties. But the combinatorial polynomials make sense for arbitrary Coxeter groups, nonrational polytopes, and nonrealizable matroids, where no corresponding algebraic variety exists. The remarkable development described in the lecture is that one can nevertheless construct the intersection cohomology groups themselves: by Soergel bimodules or moment-graph sheaves for Coxeter groups, by intersection cohomology sheaves on fans for polytopes, and by intersection cohomology modules for matroids. Thus the title “intersection cohomology without spaces” is quite literal: the algebraic and combinatorial shadows of the geometric theory continue to exist even after the underlying geometric space has disappeared.
The common framework uses sheaves of graded modules on finite posets. The strata of a variety are replaced by the elements of the poset, and the intersection cohomology sheaf is constructed inductively: after the data have been defined above an element  , the stalk at is obtained as a minimal free module mapping onto the already known boundary data. This elementary-looking construction is only the beginning. The deep part is proving that the resulting graded vector spaces have the required dimensions, and this demands combinatorial analogues of hard Lefschetz and the Hodge–Riemann relations. These theories give much more than coefficientwise nonnegativity. For example, intersection cohomology of matroids was a central ingredient in the proof of the Dowling–Wilson top-heavy conjecture: if
, the stalk at is obtained as a minimal free module mapping onto the already known boundary data. This elementary-looking construction is only the beginning. The deep part is proving that the resulting graded vector spaces have the required dimensions, and this demands combinatorial analogues of hard Lefschetz and the Hodge–Riemann relations. These theories give much more than coefficientwise nonnegativity. For example, intersection cohomology of matroids was a central ingredient in the proof of the Dowling–Wilson top-heavy conjecture: if  is the lattice of flats of a rank-
is the lattice of flats of a rank- matroid, then
matroid, then

The lecture offered a striking illustration of a major theme in modern combinatorics: geometric structures can survive, and remain powerful, even in settings where the geometry itself does not exist.
Remark (for the experts): The IH of a matroid that Tom and Nicholas outlined in the final slides (especially 23 and 24) is not the one that appears in the paper “Singular Hodge theory for combinatorial geometries”. They are currently finishing the papers with the new construction, to be posted soon.

Raghu Meka
Raghu Meka: Structure vs Randomness Redux.
Raghu Meka’s lecture was entitled “Structure vs Randomness Redux.” The classical structure-versus-randomness paradigm says that a complicated mathematical object can either be decomposed into structured pieces or shown to behave like a random object. Meka described a new and remarkably successful version of this paradigm, developed in works with Amir Abboud, Nick Fischer, Zander Kelley, and Shachar Lovett. Its central principle is

Roughly speaking, an object is spread if its density does not increase substantially when we restrict it to any large natural substructure—an affine subspace or a Bohr set for additive problems, and a rectangle for matrices. A spread object need not itself look random. The surprising assertion is that after combining two spread objects, by convolution or matrix multiplication, the result becomes close to uniform.
The first application was the classical problem of three-term arithmetic progressions. How large can a set ![A\subseteq [N]](https://s0.wp.com/latex.php?latex=A%5Csubseteq+%5BN%5D&bg=ffffff&fg=333333&s=0&c=20201002) be if it contains no distinct
be if it contains no distinct 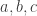 satisfying
satisfying

Behrend’s celebrated construction gives progression-free sets of density  . After a long sequence of results beginning with Roth’s theorem, the best upper bounds remained only polylogarithmic in
. After a long sequence of results beginning with Roth’s theorem, the best upper bounds remained only polylogarithmic in  . Kelley and Meka made a striking jump to the stretched-exponential bound
. Kelley and Meka made a striking jump to the stretched-exponential bound

for some absolute constant 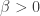 . The proof first passes to finite vector spaces. There, either
. The proof first passes to finite vector spaces. There, either  has increased density on a low-codimensional affine subspace, or is spread. In the latter case its normalized convolution satisfies, schematically,
has increased density on a low-codimensional affine subspace, or is spread. In the latter case its normalized convolution satisfies, schematically,

and this mixing forces many solutions to  . Thus one obtains a particularly clean density-increment argument: either we already have many progressions, or we move to a smaller ambient space where the set is denser.
. Thus one obtains a particularly clean density-increment argument: either we already have many progressions, or we move to a smaller ambient space where the set is denser.
A key ingredient in this theory is a new decoupling inequality. The quantities one wants to estimate often involve products such as

in which the factors are dependent because they share variables. Decoupling replaces such an expression by related expressions involving more independent copies of the variables, where analytic estimates are much easier to apply. Two further ideas are essential. Spectral positivity converts unexpectedly small values into comparable upward deviations, which can drive a density increment; and sifting uses dependent sampling to locate the substructure on which this increased density occurs. These tools make the slogan “spreadness implies mixing” applicable far beyond ordinary additive convolution.
The final application concerned finding triangles and Boolean matrix multiplication. For a tripartite graph with adjacency functions 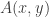 ,
,  , and
, and  , the normalized number of triangles is
, the normalized number of triangles is

Abboud, Fischer, Kelley, Lovett, and Meka proved a new spread regularity lemma: every graph can be decomposed algorithmically into a controlled number of pieces, each of which is either sparse or spread. Sparse pieces can be handled directly, while on spread pieces the product of the relevant adjacency matrices mixes, making triangle detection easy. This leads to a combinatorial algorithm for Boolean matrix multiplication, and hence for triangle detection, with running time

a super-polylogarithmic improvement over the earlier combinatorial algorithms. The broader message of Meka’s lecture was that this new version of structure versus randomness provides a common explanation for breakthroughs in additive combinatorics, communication complexity, and fast algorithms.

By Gil Kalai



